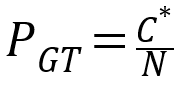一.场景和数据流分析
选择分开查询还是联合查询主要取决于具体的业务场景和数据量大小,以下是两种情况的分析:
-
联合查询:
- 合理场景:当主表和扩展表之间有较强的关联性,且查询结果依赖于两个表的数据时,联合查询可以一次性获取所有需要的数据,减少数据库交互次数,提高效率。
- 不足:如果表数据量非常大,联合查询可能会导致较大的IO压力和CPU消耗,影响查询性能。
-
分开查询:
- 合理场景:如果查询结果主要依赖主表数据,而扩展表数据只是偶尔使用;或者数据量特别大,分开查询可以通过主键关联的方式分步获取数据,降低单次查询的压力。
- 优点:在特定情况下能提高查询性能,特别是当只关心主表数据或主表数据量远小于扩展表时。
- 缺点:需要多次与数据库交互,增加了网络开销,代码逻辑相对复杂。
二、where 语句中in能包含数值的数量
WHERE 子句中 IN 条件所包含的值数量并没有统一的标准,其合适程度取决于具体的数据库管理系统以及查询性能的要求:
-
Oracle:
- Oracle 9i 中 IN 子句的元素个数限制为256个。
- Oracle 10g及以后版本中,IN列表中的元素数量通常建议不超过1000个,虽然理论上可能更高,但大量值会导致性能下降。
-
SQL Server:
- SQL Server 中 IN 子句的参数个数上限曾为2100个,但实际应用中,若因性能考虑,推荐不要使用这么多。
-
MySQL:
- MySQL 对于 IN 列表中的元素数量没有硬性限制,但大量的值同样可能导致性能问题,尤其是当无法有效利用索引时。
-
Db2:
这里没有明确提到Db2对于IN列表的具体限制数量。 -
PostgreSQL:
对于 PostgreSQL 数据库,IN 子句中可包含的值的数量没有硬性限制。这意味着在理论情况下,你可以传递任意多的值到 IN 子句中。然而,实际上,如果 IN 列表中的值非常多,这样的查询可能会导致性能问题,例如内存使用增加、CPU消耗增大、甚至查询执行时间显著延长。
尽管 PostgreSQL 不会对 IN 子句中的项目数设置固定的上限,但如果预计会有成千上万个值,应重新考虑查询设计,比如使用 JOIN 或 EXISTS 等其他查询结构,或者将值存储在一个临时表中并使用 JOIN 进行过滤,这样通常能获得更好的性能。
总之,在 PostgreSQL 中,并不存在官方文档明确指出的 IN 子句内值的数量限制,但出于性能最佳实践,应当避免在 IN 子句中包含过量的值。在处理大量数据时务必关注查询优化和性能影响。
使用 IN 子句时,当列出的值非常多时,不仅可能受到数据库特定的内在限制,还可能因为查询优化器难以高效处理而导致查询执行变慢。在实践中,如果需要处理大量值的情况,更优的选择可能是改用临时表、JOIN操作或者构建集合并使用 EXISTS 子句来替代 IN,以提高查询性能。此外,针对大型数据集,分批处理或动态SQL也是常用的优化手段。总的来说,具体合适的数量需要结合实际情况和性能测试来确定,避免一次性传入过多的参数。
三、总结
选择分开查询还是联合查询主要依据以下因素:
-
数据量大小:
- 如果主表数据量非常大,而你希望进行高效分页查询,避免过多无关数据的传输和计算,则可以先进行主表的分页查询,然后根据查询结果中获取的外键ID列表,进行批量的关联查询(IN条件查询)。这样可以确保主表查询的高效性,避免JOIN带来的性能损失。
-
查询性能:
- 联合查询(JOIN)虽然可以一次性获得所需数据,但如果关联表数据量也非常大,JOIN操作可能会导致查询变慢,尤其是全表扫描或索引不理想时。而在某些情况下,JOIN后的结果集即使进行了分页,也可能因JOIN操作而导致整体性能下降。
-
数据完整性需求:
- 如果每个主表记录都必须关联显示副表信息,那么联合查询(JOIN)更为方便,一次性返回完整的分页结果,避免二次查询。
-
内存占用和网络传输:
- 分开查询有利于控制单次查询的数据量,从而减少内存占用和网络传输成本,尤其是在数据冗余较大的情况下。
-
N+1问题:
- 使用分开查询时,务必注意避免出现N+1问题,即在循环主表结果时对副表进行逐个查询。
综上所述,如果数据量不大,或者JOIN操作不会导致明显性能瓶颈,且一次性获取所有关联数据符合业务需求,可选用联合查询;反之,如果主表数据量大且性能敏感,建议首先进行主表分页查询,然后通过批量查询或者其他方式(比如懒加载)获取关联数据,同时注意优化查询性能。在实际开发中,还需要结合具体应用场景和性能测试来决定最佳方案。